Ich habe seit September 2020 einen Oura Ring und in der Zeit 2561 Datensätze an Schlafdaten gesammelt.
In diesem Beitrag möchte ich euch ein wenig über meine Erfahrungen mit Oura erzählen und meine Schlafdaten besprechen, die ich mit statistischen Methoden ausgewertet habe.
Methodik
Ich benutze das Programm R für die statistische Datenanalyse. R ist ein Statistikprogramm, ähnlich wie SPSS, das man mit der gleichnamigen Programmiersprache R steuert. (Mehr dazu hier: TU Dresden)
R hat den Vorteil, dass es Open Source ist. Ich benutze es in Kombination mit Rstudio als grafische Oberfläche. (Mehr dazu)
So bin ich an meine Daten gekommen
Wenn du deine Oura Daten exportieren möchtest, gehst du so vor:
- Log dich auf cloud.ouraring.com ein
- Unter „My Account“ kommst du zu
- Export Data
- dort kannst du deine Dateien als CSV oder JSON Datei herunterladen
Meine Schlafdaten entnehme ich der Datei sleep.csv
Mit ChatGPT habe ich den kompletten Datensatz umgewandelt und die unnötigen Spalten gelöscht.
Das ginge natürlich auch in einem Tabellenkalkulationsprogramm wie Excel oder Numbers, aber ChatGPT war einfach schneller.
Diesen Prompt habe ich dafür genutzt:
Nimm diese CSV Datei und bau einen Datensatz für R in dem du die Spalten "day", "light_sleep_duration", "deep_sleep_duration", "rem_sleep_duration", "total_sleep_duration" speicherstChatGPT gibt mir dann eine CSV Datei zum Download. Leider hat er es nicht geschafft einen Datensatz im „.RData“-Format zu erstellen. Das ist aber nicht weiter tragisch, weil ich in R auch problemlos einen CSV-Datensatz importieren konnte.
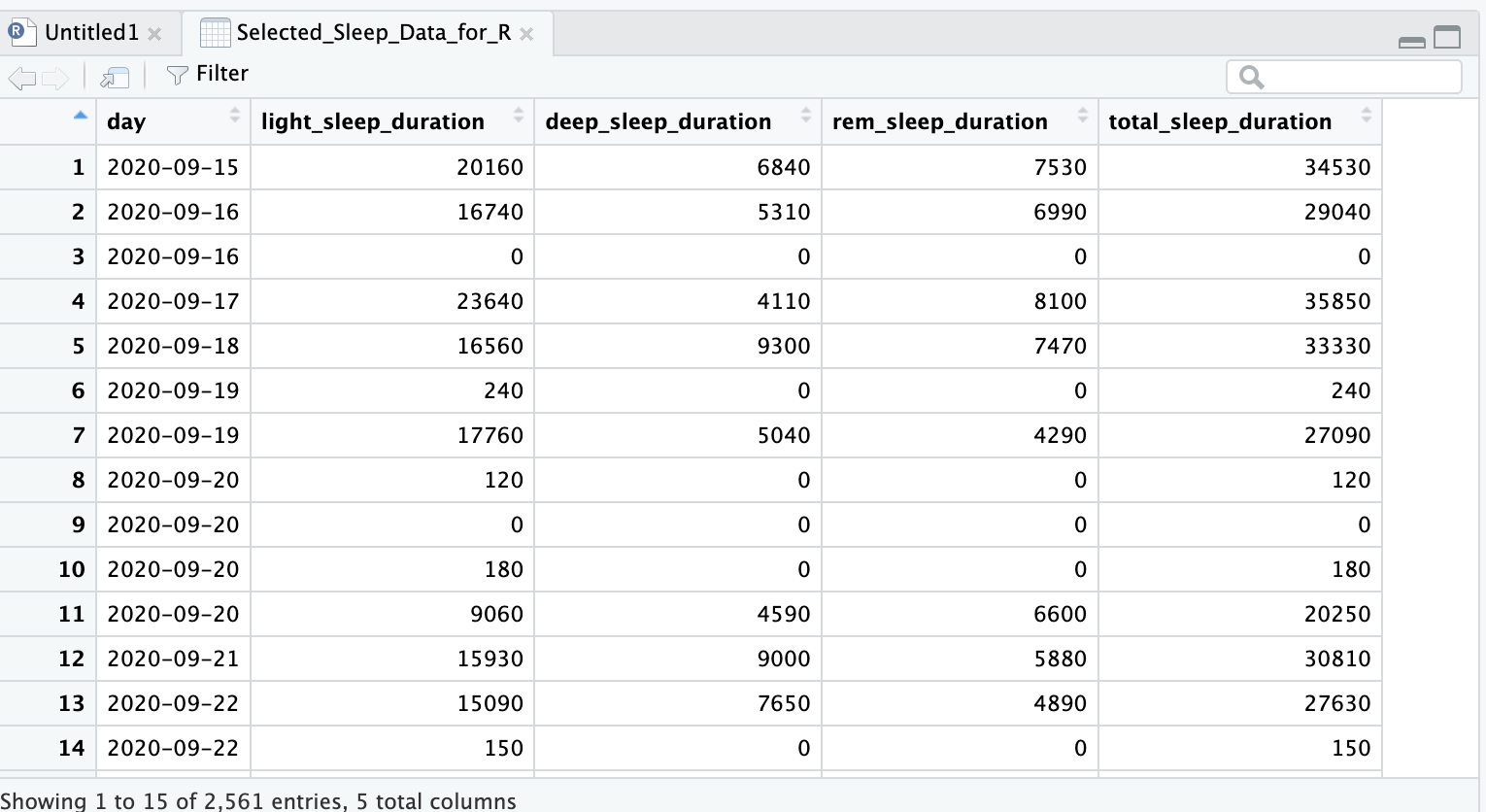
So sieht der Datensatz aus. Man sieht, es fehlen ein paar Nächte.
Es gibt Möglichkeiten in R für die Analyse nur die Zeilen zu berücksichtigen, die nicht 0 sind. Aber ich bin faul und werde noch einmal ChatGPT bemühen. Bevor ich die neue Datei importiere lösche ich die Alte mit
rm(list = ls())Nach erneutem Import sind es nur noch 2110 Datensätze. Was natürlich immer noch mehr als 4 Jahre sind und dem geschuldet ist, dass Oura für aufgeteilten Schlaf (Nachtschlaf + Kurze Tagschlaf perioden) 2 Datensätze anlegt. Für diese Auswertung sollte das aber nicht ganz katastrophal sein.
Statistische Auswertung
Grafische Aufbereitung
Mit R lassen sich Daten grafisch aufbereiten. Dafür muss man das Paket ggplot2 aktivieren.
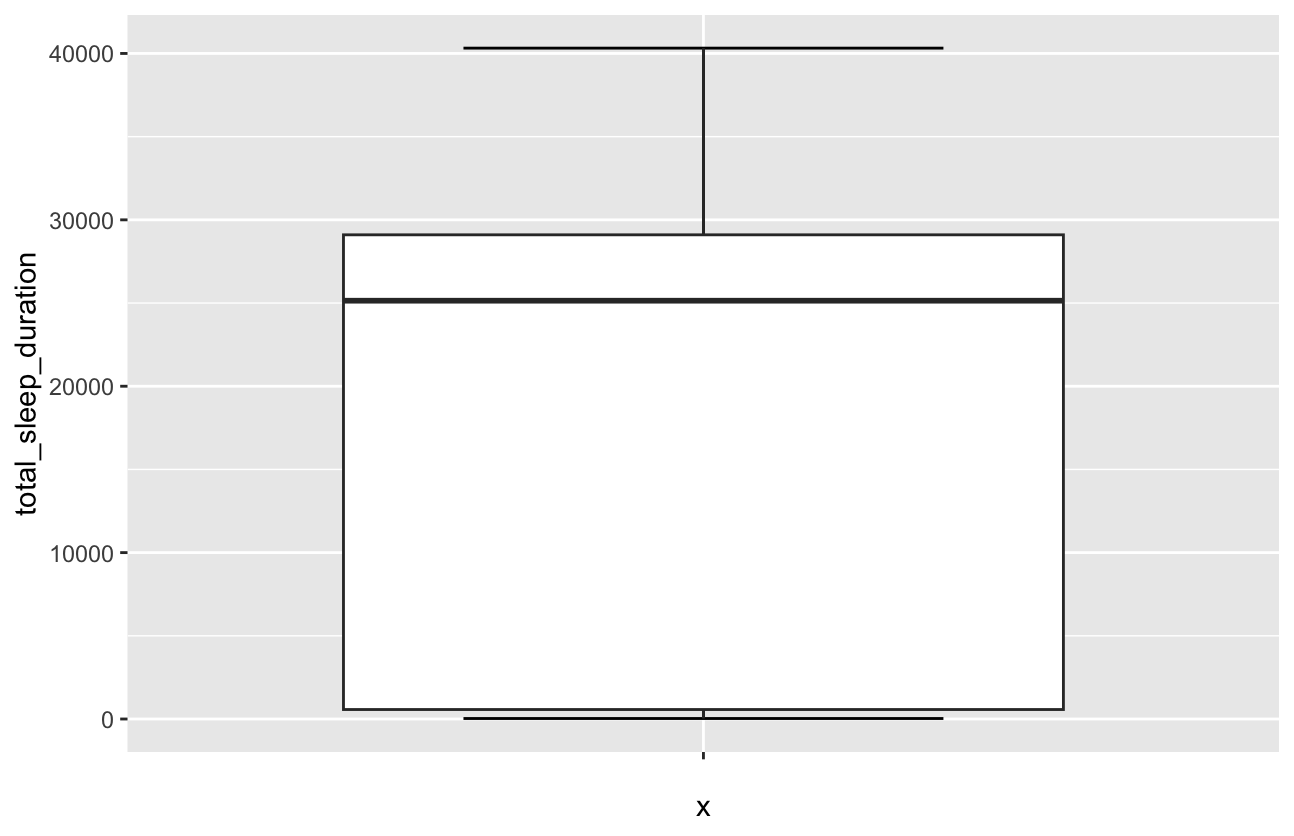
Ich möchte mir jetzt ein Boxplot von meiner Schalfdauer erstellen:
Wenn man sich jetzt in R ein Histogramm ausgeben lässt, sieht man, wie unsauber der Datensatz von Oura eigentlich ist…
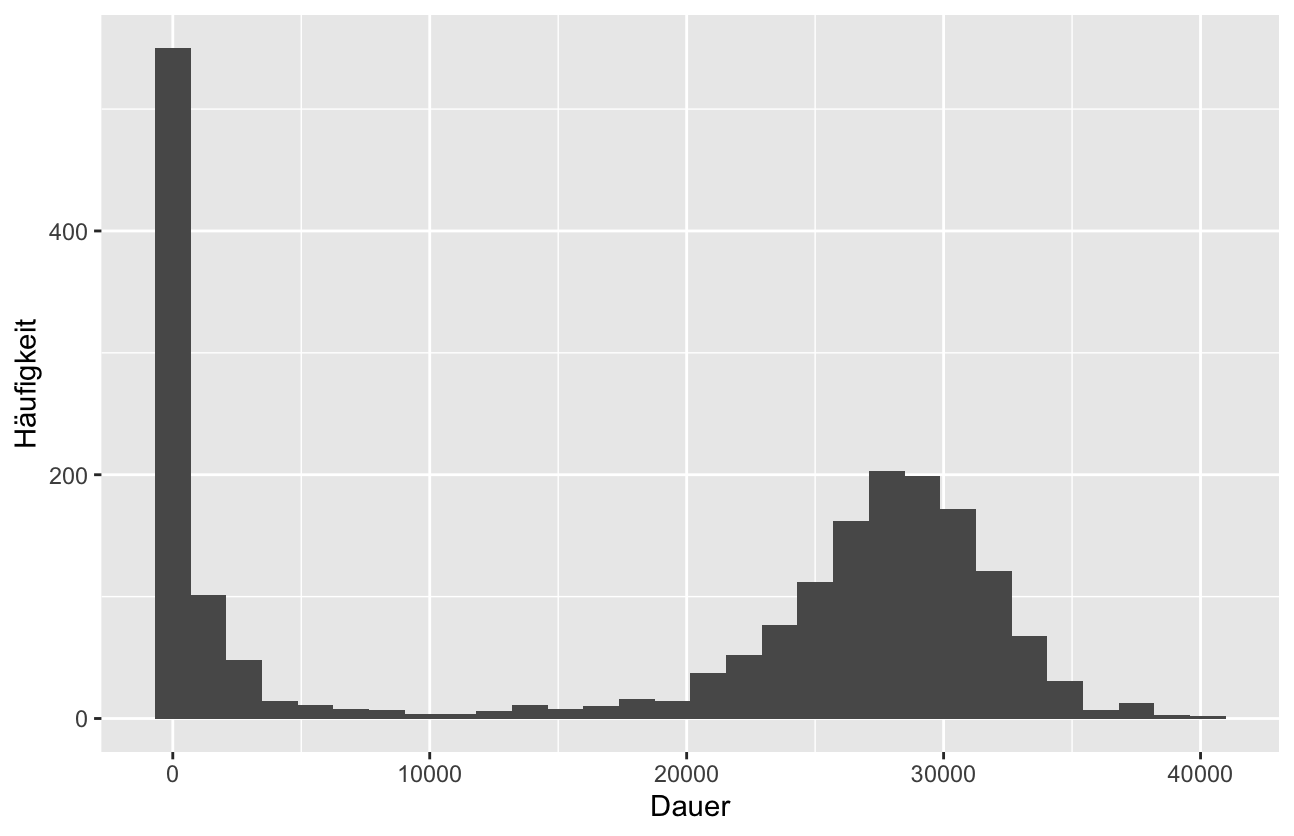
Die Dauer scheint Oura in Sekunden zu erfassen. 20.000 Sekunden entsprechen etwa 5,5 Stunden.
Daten weiter aufbereiten
Filtered_Sleep_Data_for_R_1_ <- Filtered_Sleep_Data_for_R_1_[Filtered_Sleep_Data_for_R_1_$total_sleep_duration >= 14400, ]Mit diesem Befehl lösche ich jetzt alle Einträge aus dem Datensatz, in denen Oura weniger als 4 Stunden Schlaf aufgezeichnet hat.
Jetzt gebe ich mir noch mal das Histogramm aus und:
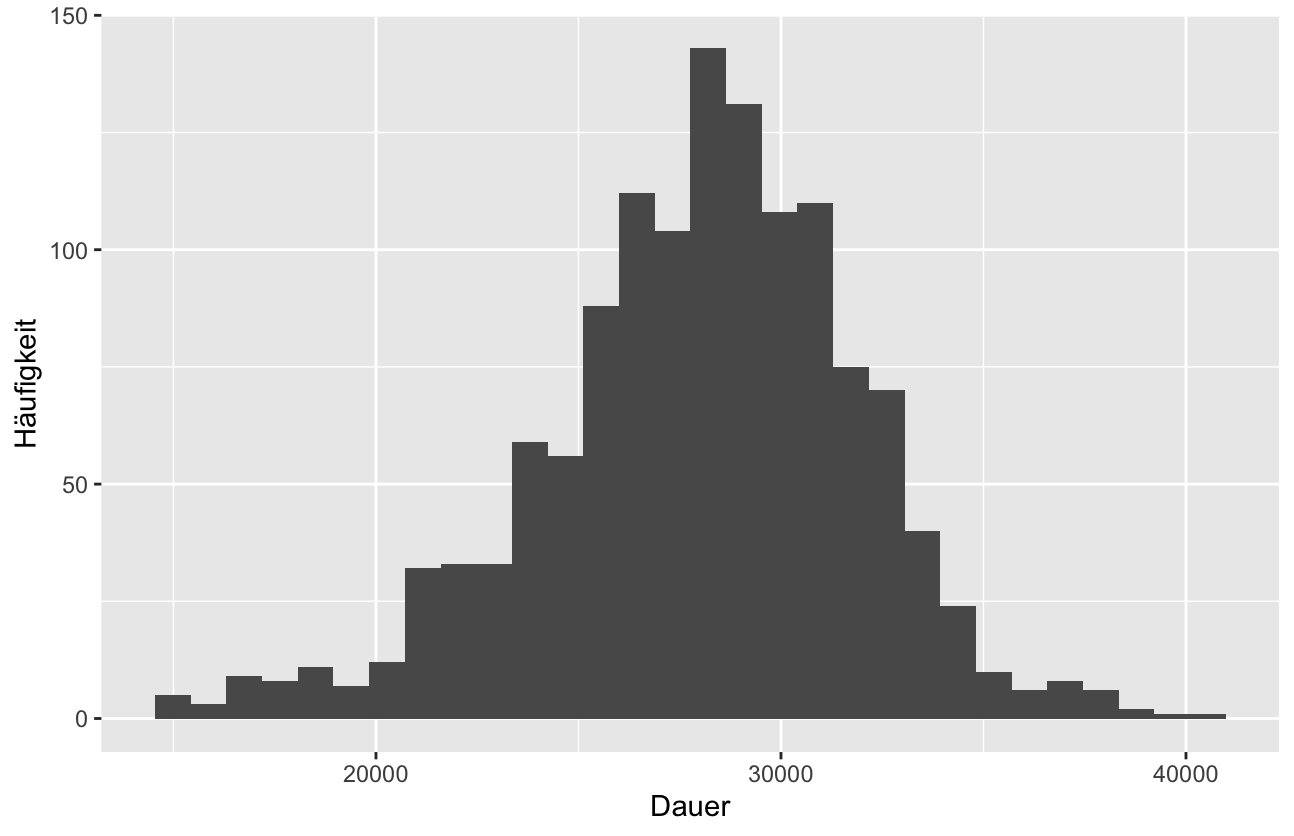
Das sieht doch viel besser aus.
Schauen wir uns jetzt meine Schlafdaten im Detail an.
1346 Nächte mit Oura
Zur besseren Übersicht könnten wir uns die Fünf-Punkte-Zusammenfassung ausgeben lassen. Die Fünf-Punkte-Zusammenfassung enthält:
- Minimum
- 1 Quartil
- Median (also 2. Quartil)
- 3 Quartil
- Maximum
Für den Gesamtschlaf aus dem Oura-Datensatz würde das so aussehen:
[1] 14760 25710 28290 30630 40320Die Nacht (in diesem bereinigten Datensatz) mit am wenigsten Schlaf wäre die mit 14.760 Sekunden Schlaf (knapp über 4 Stunden), der Median liegt bei 7 Stunden und 51 Minuten. Gar nicht schlecht!
Das heißt: betrachtet man die Schlafdaten aus ungefähr 3 Jahren und 8 Monaten, liegen genau so viele Nächte mit weniger Schlaf als 7 Stunden und 51 Minuten vor, wie Nächte mit mehr Schlaf als 7 Stunden und 51 Minuten vorliegen. Ich finde das ist eine sehr gesunde Leistung. Mein Maximum liegt bei 11 Stunden und 12 Minuten.
Allerdings interessiere ich mich noch für mehr Werte. Ich wüsste gerne das arithmetische Mittel (also den Mittelwert) meiner Nächte und die Standardabweichung.
Methodik:
Ich verwende die Befehle mean() und sd(), um mir in R für die einzelnen Daten die Mittelwerte und Standardabweichungen auszugeben. Die Werte erhalte ich in Sekunden gemessen. ChatGPT rechnet sie mir in Stunden bzw. Minuten um, weil ich zu faul bin, es selbst in den Taschenrechner einzugeben 🤡🤡
Schlafdaten Mittelwerte und Standardabweichungen
| Kennwert | Mittelwert | Standardabweichung |
| Gesamtschlaf | 7 Stunden 46 Minuten | 1 Stunde 5 Minuten |
| REM-Schlaf | 1 Stunde 40 Minuten | 27 Minuten |
| Tiefschlaf | 1 Stunde 48 Minuten | 33 Minuten |
| Leichtschlaf | 4 Stunden 17 Minuten | 54 Minuten |
Man sieht, insgesamt ist bei meiner Schlafbeständigkeit noch Luft nach oben.
Wenn wir jetzt noch lustig sind, können wir uns den Produkt-Moment-Korrelationskoeffizienten (fancy für: die Korrelation) ausgeben lassen.
Trommelwirbel…
cor(Filtered_Sleep_Data_for_R_1_$deep_sleep_duration, Filtered_Sleep_Data_for_R_1_$total_sleep_duration, use="pairwise.complete.obs")➡️ r=0.1313983
Das hat mich ehrlich gesagt ziemlich überrascht. Ich bin fest davon ausgegangen, dass es einen starken Zusammenhang zwischen der Schlafmenge und Tiefschlaf gibt. Aber eine Korrelation von 0,1314 ist ein schwacher Zusammenhang.
Anders sieht es beim REM-Schlaf aus. Hier kommen wir auf r = 0,7419429 DAS ist ein starker Zusammenhang.
Erklärungsversuch
Tiefschlaf findet gehäuft in der ersten Hälfte der Nacht statt. Eine mögliche Erklärung ist, dass die Nächte, in denen ich weniger geschlafen habe, solche sind, in denen ich vor allem morgens früher wach war. Dadurch habe ich auch in kürzeren Nächten noch mehr Tiefschlaf bekommen als REM-Schlaf.
Alternative Hypothese mit R testen
Spannend wäre ein Datensatz, in dem man den Tiefschlaf mit der Gesamtschlafzeit der VORHERIGEN Nacht vergleicht und daraus eine Korrelation bildet.
Dazu können wir die Tabelle mit den Schlafdaten duplizieren und zum Beispiel mit Excel oder Numbers bearbeiten oder ChatGPT die Arbeit machen lassen.
In diesem Fall geht es tatsächlich mit Excel oder Numbers schneller.
Ich exportiere mir vorher den aktuellen Datensatz als CSV aus R, weil wir ja über R vorher einige Datensätze gelöscht hatten und die Daten sonst komplett durcheinander geraten. Das mache ich mit dem Code:
write.csv(Filtered_Sleep_Data_for_R_1_, file = "tiefschlaf-verschoben.csv", row.names = TRUE)
Jetzt bearbeite ich die Datei schnell in Numbers, füge oben eine Zeile mehr ein, ziehe die Spalte Gesamtschlaf eine Zeile nach oben. Lösche die erste und die letzte Zeile.
In jeder Zeile habe ich jetzt den Tiefschlaf, Leichtschlaf, REM-Schlaf für die jeweilige Nacht und die Gesamtschlafdauer der vorherigen Nacht.
Meine Hypothese ist, dass die Tiefschlaf dauer negativ mit der Gesamtschlafdauer der vorherigen Nacht korreliert.
und Kaboom: r=-0.07628142
Je weniger Gesamtschlaf am Vortag, desto mehr Tiefschlaf in der nächsten Nacht.
Wobei 0,07628 ein noch schwacherer Zusammenhang ist, als das r am Vortag.
Fazit: Es sieht so aus, als könnte man den – normalerweise – naheliegenden Zusammenhang zwischen Gesamtschlafdauer und Tiefschlafdauer anhand der Daten nicht eindeutig beweisen. Nur, weil es keine Korrelation gibt, ist das aber kein Beweis für einen nicht vorliegenden Zusammenhang, da es andere Störfaktoren geben kann oder auch ein nicht-linearer Zusammenhang vorliegen könnte.
Spannend ist trotzdem, das ganze noch mal für den REM-Schlaf durchzutesten:
Hier hatten wir einen starken Zusammenhang zwischen mehr Gesamtschlaf und mehr REM-Schlaf. Vergleicht man die Daten des Vortags ist der Zusammenhang auf einmal noch geringer. r = 0.003887668
Wie ernst sollte man die Daten aus Oura nehmen?
Insgesamt ist es unterhaltsam mit den exportieren Daten aus Oura zu spielen und nach Zusammenhängen zu suchen. Man sollte die Daten aber nicht zu ernst nehmen, da Oura nicht die Genauigkeit eines Schlaflabors erreicht. Zur Genauigkeit der Oura Schlaferkennung ist hier ein Paper erschienen: https://www.sciencedirect.com
Auch wenn Oura vielversprechend ist, haben die Daten ihre Schwäche. Die Autoren schreiben: „Sleep staging accuracy ranged between 75.5 % (light sleep) and 90.6 % (REM sleep).“
Das ist mit dem Oura Generation 3 eine starke Verbesserung zur 2. Generation, die nur auf eine Genauigkeit von rund 60% kam (https://www.mdpi.com/1424-8220/22/16/6317).